













賀!!本系陳仁暉教授指導碩士及博士生,於影像人體辨識與追蹤研究,刊登於國際電腦影像處理重要期刊Image and Vision Computing。
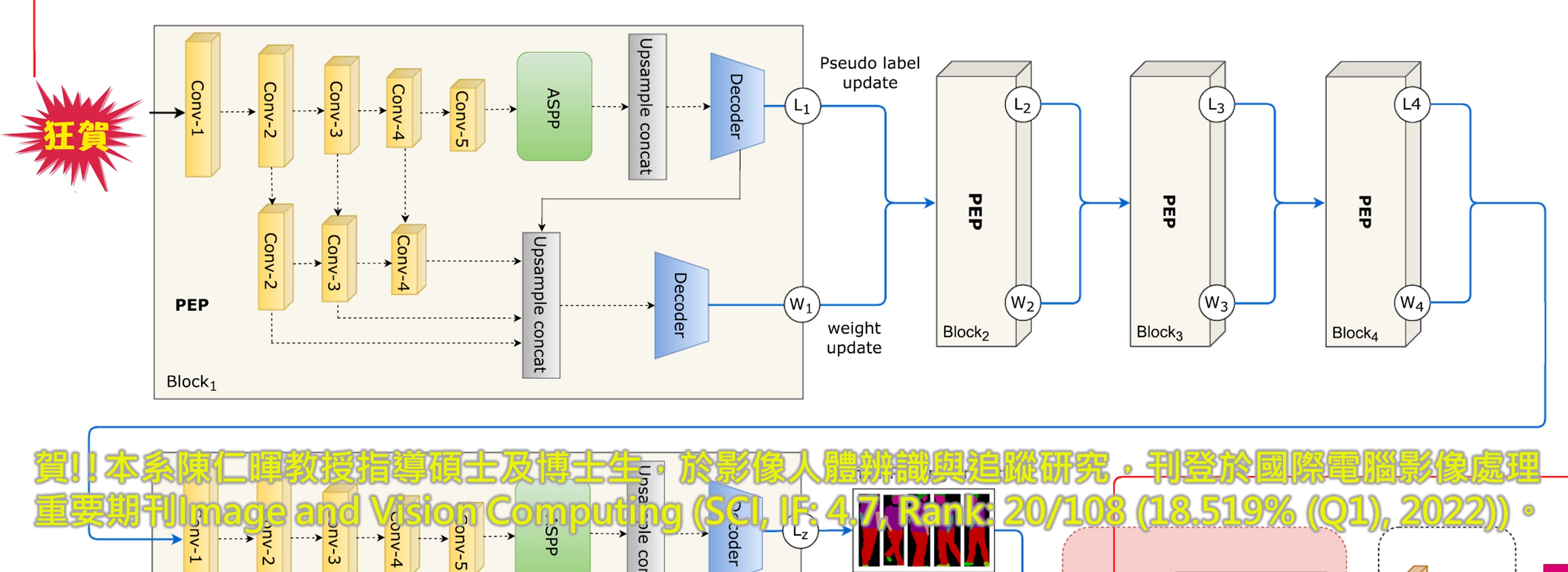
►賀!!本系陳仁暉教授指導碩士及博士生,於影像人體辨識與追蹤研究,刊登於國際電腦影像處理重要期刊Image and Vision Computing (SCI, IF: 4.7, Rank: 20/108 (18.519% (Q1), 2022))。
Obinna Agbodike, Weijin Zhang, Jenhui Chen*, and Lei Wang, "A Face and Body-shape Integration Model for Cloth-Changing Person Re-Identification," Image and Vision Computing, vol. 140, p. 104843, December 2023. (SCI, IF: 4.7, Rank: 20/108 (18.519% (Q1), 2022) in Computer Science & Software Engineering) DOI: 10.1016/j.imavis.2023.104843
Among the existing deep learning-based person re-identification (ReID) methods, human parsing based on semantic segmentation is the most promising solution for ReID because such models can learn to identify fine-grained details of different body parts or apparel of a target semantically. However, intra-class variations such as illumination changes, multi-pose angles, and cloth-changing (CC) across different non-overlapping camera viewpoints present a crucial challenge for this approach. Among these challenges, a person CC is the most distinctive problem for ReID models, which often fail to associate the target in new cloth against the learned feature semantics of the previous cloth worn in a different timeline. In this paper, we propose a face and body-shape integration (FBI) network as a tactical solution to address the long-term person CC-ReID problem. The FBI comprises hierarchically stacked parsing and edge prediction (PEP) CNN blocks that generate fine-grained human-parsing output at the initial stage. We then aligned the PEP to our proposed model agnostic plug-in feature overlay module (FOM) to mask cloth-relevant body attributes except the facial features pooled from the input sample. Thus, our human parsing PEP and FOM modules are attuned to discriminatively learn cloth-irrelevant features of the target pedestrian(s) to optimize the effectiveness of person ReID in solitary or minimally crowded areas. In our extensive person CC-ReID experiments, our FBI model achieves 83.4/61.8 in R1 and 91.7/65.8 in mAP evaluation results on the PRCC and LTCC datasets, respectively; thereby significantly out-competing several previous state-of-the-art ReID methods, and validating the effectiveness of the FBI.
在現有的基於深度學習的行人重識別(ReID)方法中,基於語義分割的人體解析是最有前途的ReID解決方案,因為此類模型可以學習從語義上識別目標不同身體部位或服裝的細粒度細節。然而,不同非重疊攝影機視點之間的類內變化(例如照明變化、多姿勢角度和布料更換 (CC))對這種方法提出了嚴峻的挑戰。在這些挑戰中,人員 CC 是 ReID 模型最獨特的問題,它通常無法將新衣服中的目標與不同時間線中所穿的先前衣服的學習特徵語義相關聯。在本文中,我們提出了一種臉部和體型整合(FBI)網路作為解決長期人員 CC-ReID 問題的戰術解決方案。FBI 包含分層堆疊的解析和邊緣預測 (PEP) CNN 模組,可在初始階段產生細粒度的人類解析輸出。然後,我們將 PEP 與我們提出的與模型無關的插件特徵覆蓋模組 (FOM) 對齊,以掩蓋除從輸入樣本中匯集的面部特徵之外的與布料相關的身體屬性。因此,我們的人體解析 PEP 和 FOM 模組能夠有區別地學習目標行人的與服裝無關的特徵,以優化行人 ReID 在孤獨或最少擁擠區域中的有效性。在我們廣泛的人體 CC-ReID 實驗中,我們的 FBI 模型在 PRCC 和 LTCC 資料集上的 R1 評估結果分別達到 83.4/61.8 和 mAP 評估結果 91.7/65.8;從而顯著超越了先前幾種最先進的 ReID 方法,並驗證了 FBI 的有效性。